

This page contains materials used at JADH workshops held on August 29, 2019.
The purpose of this workshop is to learn how to use a morphological analysis system that can be used in Chinese, how to use a vocabulary index creation program, and text search using regular expressions. Let’s actually use each tool while operating the PC.
このワークショップの目的は中国語で使える形態素解析システムの使い方、語彙索引の作成プログラムの使い方、正規表現を使ったテキスト検索をいっしょに学んでいこうというものです。PCを操作しながら実際にそれぞれのツールを使ってみましょう。
INDEX
- Overview of morphological analysis and Morphological analysis practice
- INDEX CONVERTER practice
- Regular expression search practice using a text editor
- 形態素解析概要と実践
- INDEX CONVERTER実践
- テキストエディタを使った正規表現検索実践
1.Morphological Analysis
First, I will briefly introduce some of the Chinese morphological analysis that can be easily used in web browsers.
まずはじめにウェブブラウザで簡易に利用できる中国語の形態素解析について簡単にいくつか紹介します。
morphological analysis
SAMPLE1
李明,你家在哪儿?我家在北京。你家有几口人?都有什么人?我家有五口人,爸爸、妈妈、哥哥、妹妹和我。你妹妹多大了?我妹妹今年十三岁了。
SAMPLE2『北京官話全編』 第1章 1900? 深澤進
阿哥,您是怎麽了,臉上這麽不高興的樣兒,不是又挨打了,
曖,没挨打,因為我纔上一個親戚那兒去,一進門兒,看見他們矮矮屋的,屋裏很腌髒,桌子上的埃塵,也不撢他們家裏的人,都帶着哀泣的樣子,我一問,纔知道他們家近來日子難過,每天吃一頓,挨一頓,他們因我這一問,就把目下的光景,挨次兒的都對我説了,並且還哀求我,帮助他點兒錢,接續接續,他免得挨餓,你想我若是有錢,帮他點兒,也没甚麽妨礙,無奈我現在也是赤手空拳,呌我怎麽帮他,要是不帮他,看他那哀慘的樣兒,實在令人哀憐,况且他那麽哀告,礙着情面也不好駁囬,所以我臉上帶着不高興的樣兒
啊,原来是這麽着,我想您既是看見他們那麽可哀憐,又和您是親戚,您又不是愛財如命的人,就是帮他點兒錢,於你既有好處,於他也省得挨餓,日後他對人説起来,必説您愛人如己,人聽見他的話,豈有不佩服愛慕的麽,
2.Index Converter
A tool that creates a vocabulary index by adding page information to morphologically analyzed text data.
形態素解析したテキストデータにページ情報を加えて全語彙の索引を作成するツール。
http://www.chlang.org/contents/index-converter/
This program is written in JavaScript and has been confirmed to work with Chrome and Firefox.
このプログラムはJavaScriptで作成されており、ChromeとFirefoxでの動作を確認しております。
Download sample data for use in the workshop
- 『北京官話全編』第1章~第10章(Text Data)
- 『北京官話全編』第1章~第10章(image data)
- START DASH第1課~第14課 (Text Data)
- START DASH第1課~第14課 (image data)
3.Search My Corpus using a text editor
If you have time, let’s experience a Chinese search using simple regular expressions.Regular expressions are great for preprocessing, text formatting, and searching.
時間があれば簡単な正規表現を用いた中国語の検索を体験してみましょう。正規表現は、前処理や文章の整形、検索などに力を発揮します。
Data preparation and folder search
Search method using regular expressions
^(克拉)
^是符合文字列的前头和行的前头。
^ABC符合行头里的ABC。
^这是符合行头里的。
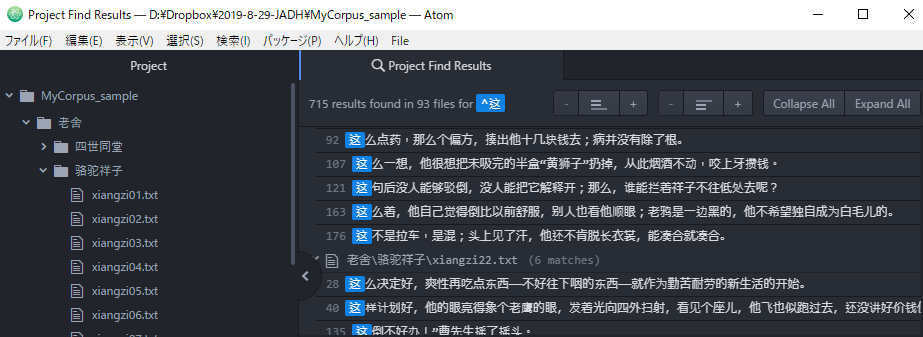
$ (美元记号)
$ 对应文字列末或行尾。
ABC$对应行尾是ABC的文字列。
“回来。$”对应行尾是”回来。”的文字列
$对应文字列末或行尾。
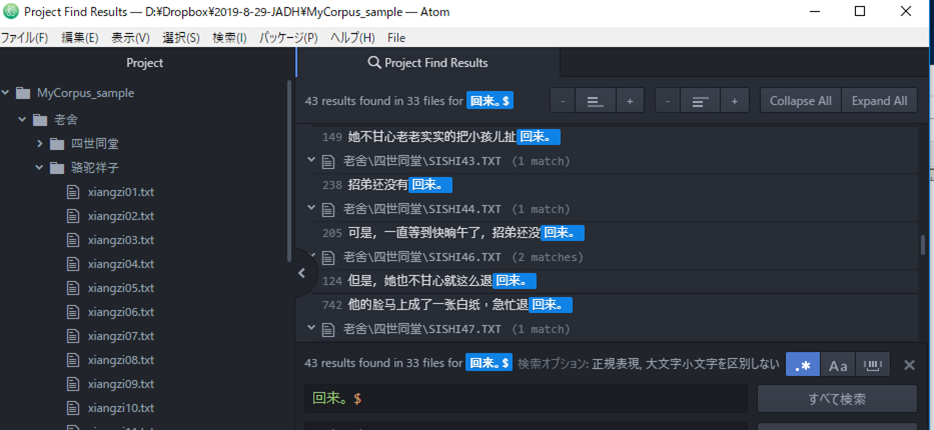
.(句号)
对应.和换行代码(n)以外的任意的1个文字。
三个句号比如…的话对应任意的三个文字。
a.C对应abc、acc、adc・・・等
比如“这.是”对应“这不是,这也是,这都是,这还是,这个是,这本是”…等文字列。
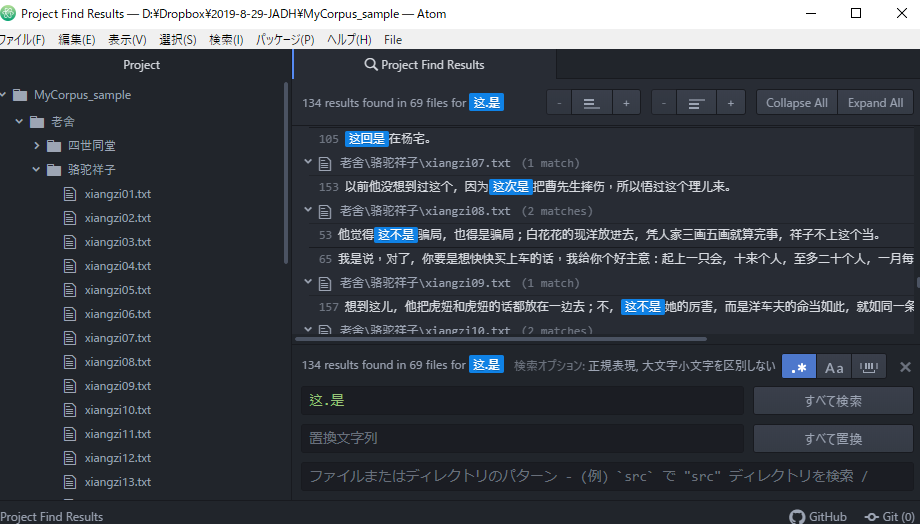
查“离合词”有用。比如,”结.婚”、”生..气”对应”结了婚、结过婚” ;”生他的气”、”生儿子气”等文字列。另外”一.二.”则对应”一干二净、一清二白、一穷二白”等文字列。一个句号能表示换行以外的任意的一个文字。还有像后述的,句号并用”*+?”等的记号能做到更有效率的检索 。
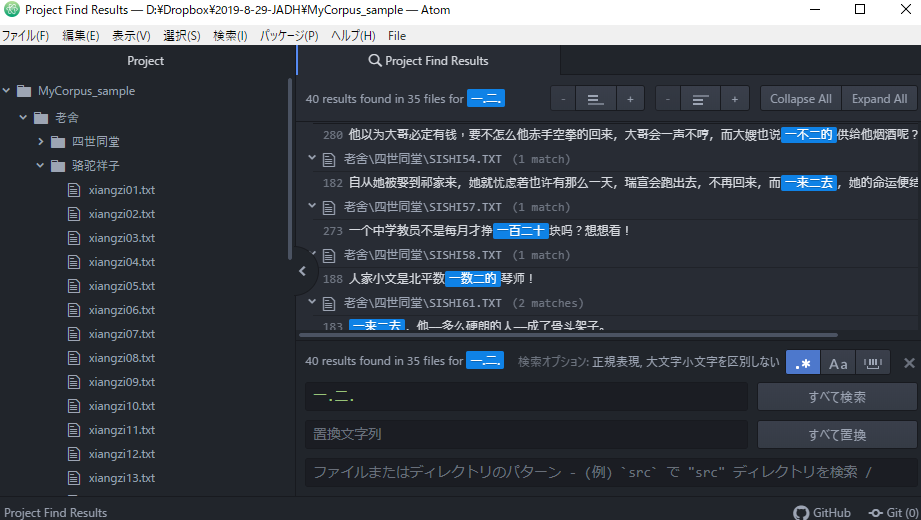
*(星号)
* 对应前面的一个文字(正则表达式)的0次以上重复。(包含0)
ab*c对应ac、abc、abbc、abbbc、…
.*对应 包含空文字列的任意文字列。
比如”结.*婚”对应”结婚”、”结了婚”、”结完了婚”、”结过一次婚”、”结过一次”
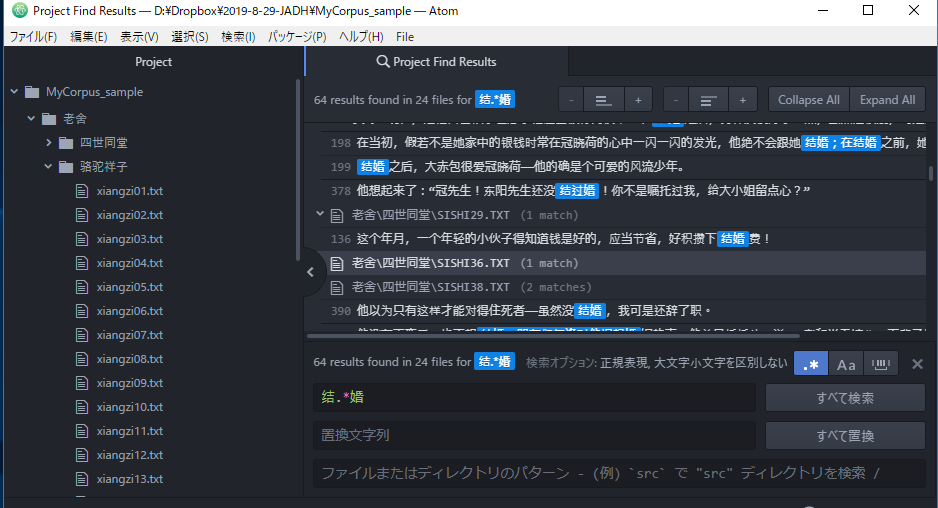
+(加号)
+对应前面的一个文字(或正则表达式)一次以上的重复(不含0次)
ab+c对应abc、abbc、abbbc、…(不对应ac)
.+对应任意的一个文字。
比如”回.+来”对应”回家来”、”回北京来”、”回到了阔别已久的故乡来”、…等文字列,而不对应“回来”。
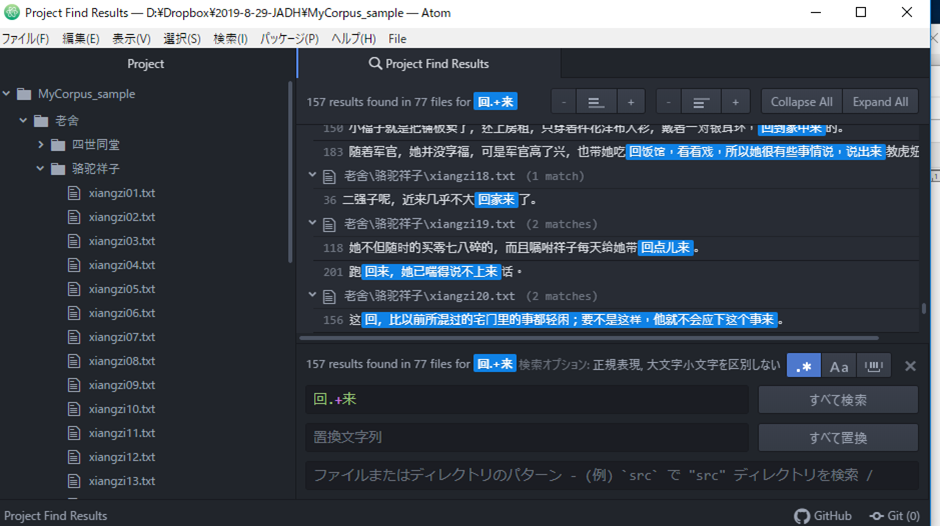
?(问号)
?表示正前面的一个文字(或正则表达式)的0次以上的出现。?被叫做重复的隐喻文字。其实不重复两次以上的。
ab?c对应ac、abc,
比如“看一?看”对应“看看”、“看一看”
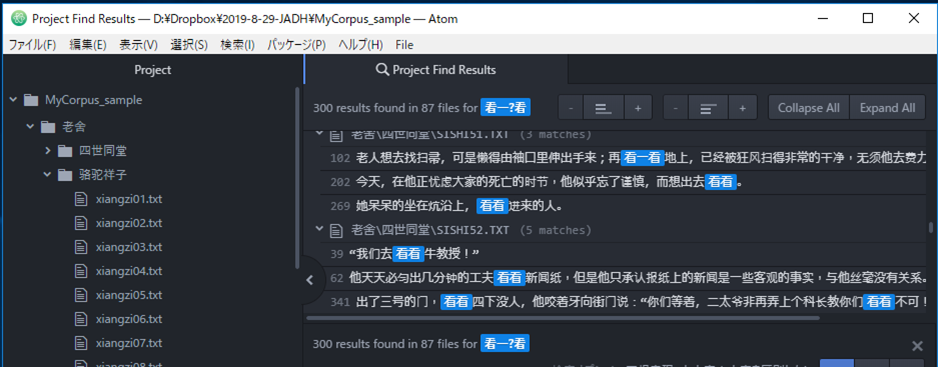
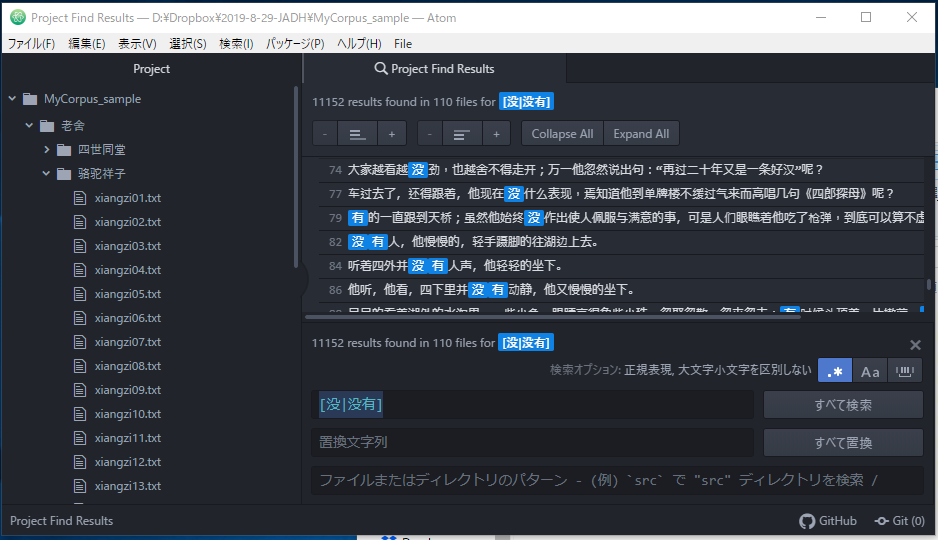
|(选择)
|表示选择文字列。
“没|没有”对应“‘没’或‘没有’” 。
[](括号)
表示括号内的任意的一个文字。也可以指定范围。
[abcdef]对应“a~f”的任意1个文字
[あいうえお]对应「あ~お」的任意1个文字还有一种是用“-”指定范围 。“-” 拥有特殊意思。
[0-9] 表达任意一个数字
[A-Za-z]表达任意一个英文字母
( )(圆括弧)
( )有两种意思,一个是集合化的意思,比如李(先生|同学|师傅)对应李先生,李同学,李师傅等。
(高兴)+对应高兴高兴,高兴高兴高兴…等
还有一种用法称作“参照后方”(back reference),指定引用\1~\9的部分。数字表示对应第几个()。
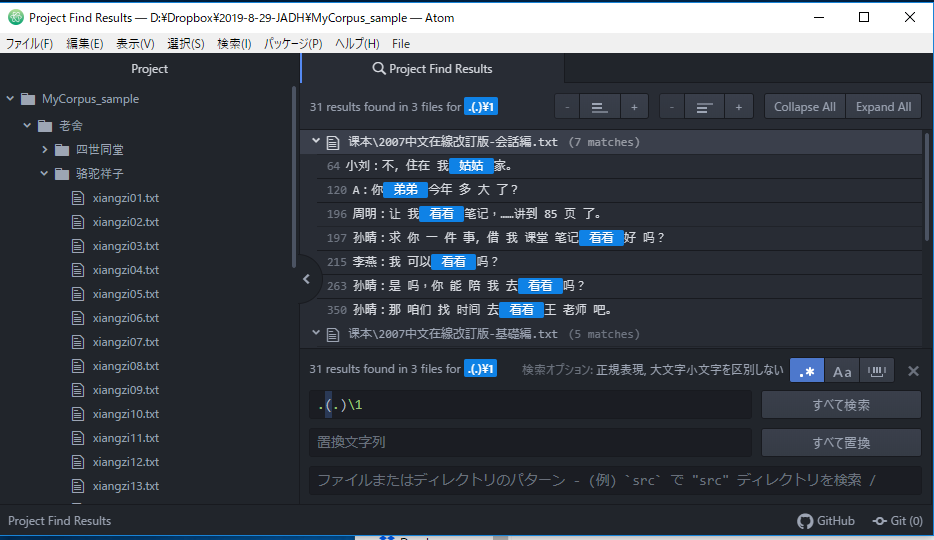
{ } (重复)
{是指定某规定次数以上的重复隐喻文字。{n}是符合正前面的一个文字(或正则表现)的n次以上的重复。{1,3}是符合正前面的一个文字(或正则表现)一次到三次的重复。
a{1,3}对应a和aa、aaa
{min,
max}对应正前面的一个文字(或正则表达式)的min次~ma次的重复。如果不输入Min的数量则被解释为0次,同样不输入max的数量则被解释为∞次(无穷)*和+、?、{min,max}作为重复的模式表示最大次数的重复、正后面添加?能停止在最小次数重复。
*?表示正前面的正则表达零次以上的重复(最小次数,就是说优先零次
+?表示正前面的正则表达一次以上的重复(最小次数,就是说优先一次)
??表示正前面的正则表达的零次或一次以上的重复。(最小次数,就是说优先零次)
{min,max}?对应正前面的正则表达的min次〜max次的重复
检索汉语的技巧
•单音节词的检索
量词的检索, 如果要检索使用“个”的名词怎么查好?下面检索什么词汇?
“[很真太]大”
检索汉语的技巧
跟“着、了、过”等的助词一起检索
“看一看、尝了尝”
离合词的检索
“结婚、生气、请客、洗澡”那样的形式, “结了婚、结过一次婚、生闷气、生孩子的气、请他客、请老王的客、洗完澡、洗一个热水澡”
